How Google Works?
최근 웹크롤러에 대해 공부하면서, 웹브라우저에서 검색을 하고 결과물을 받아보던 익숙한 여정에 대해 좀 더 알아보고자 한다. 검색의 대부 구글을 통해 살펴보겠다.

Google에서 검색할 때, 우리는 실제로 웹을 검색하는 것이 아니다. 구글의 웹 index를 검색하는 것이다. 다시 말해, 구글은 최대한 많은 웹을 index로 생성하기 위해 노력한다. 이 작업을 위해, 구글에서는 '스파이더'라 부르는 소프트웨어가 이 작업을 한다. 웹 페이지 몇 개를 가져오는 것에서 시작해서, 그 페이지에 연결된 링크를 따라간다. 그 링크가 가리키는 또 다른 새로운 페이지들을 또 가져오고 하는 과정을 무한히 반복하여, 구글은 수천 대의 컴퓨터에 거쳐 수십억 페이지로 된 방대한 규모의 웹 index를 생성했다.
원하는 검색어를 검색창에 검색하고 엔터를 누르면, 구글의 소프트웨어는 각 검색어를 포함하는 모든 페이지를 찾기 위해 방대한 구글의 index들을 검색한다. 이 때 가능한 검색결과가 수십만 개의 결과가 나오는데, 이 때 구글은 내가 원하는 대로 문서 몇 장으로 압축해서 보여준다. 어떻게? 이 소프트웨어는 추려진 index들에게 200가지가 넘는 질문을 한다. 어떤 페이지가 검색어를 몇 번 포함하는지, 검색어가 나오는 곳이 제목인지, URL인지, jason에서 바로 나오는지, 페이지에 유사어가 나오는지, 해당 페이지가 양질의 웹사이트로부터 나온건지 저퀄리티 웹사이트/스팸인지, 이 페이지의 *페이지랭크는 어떤지 등이다. 구글의 창립자인 Larry Page와 Sergey Brin이 고안한 공식으로, 연결된 외부 링크의 수와 그 링크의 중요성 등을 조사해서 한 웹페이지의 중요성을 평가하는 것이다. 마지막으로 이 모든 요소를 종합하여, 각 페이지의 전반적인 평점을 매기고 이에 따라 검색결과를 내보내게 되는 것이다. 검색어 입력부터 아웃풋 출력까지 약 0.5초가 걸린다.
* 페이지랭크(PageRank)는 월드 와이드 웹과 같은 하이퍼링크 구조를 가지는 문서에 상대적 중요도에 따라 가중치를 부여하는 방법으로, 웹사이트 페이지의 중요도를 측정하기 위해 구글 검색에 쓰이는 알고리즘이다.

페이지 랭크에 대해 좀더 알아보자. 방대한 정보 속에서 사용자에게 원하는 정보를 제공하기 위해 구글이 수천억개의 검색 색인(index)을 정리해두고 분류하는것이 바로 구글의 랭킹 시스템이다. 이 랭킹 시스템은 여러개의 알고리즘으로 구성되어 있다. 구글의 검색 알고리즘은 검색어의 단어, 페이지의 관련성 및 유용성, 출처의 전문성, 사용자의 위치 및 설정과 같은 다양한 요소를 고려한다.
예컨대 시사 관련 검색어의 경우 사전 정의 검색어보다 최신 콘텐츠인지 여부가 더 중요하다. 검색 알고리즘이 높은 수준의 관련성 및 품질 기준을 충족할 수 있도록 구글은 엄격한 가이드라인을 따르는 숙련된 외부 검색 품질 평가자 수천명이 동원시키기고 있다. 가이드라인은 모두에게 공개되어 있다. 해당 가이드라인 Page Quality (PQ) rating과 and Needs Met (NM) rating에 근간을 두고 있다.

검색어 의미 분석
우수한 답변 제공을 위해 검색어의 의미를 이해하는 것이 중요하다. 따라서, 관련 정보가 포함된 페이지를 찾기 위한 첫 번째 단계는 검색어에 포함된 단어가 무엇을 의미하는지 분석하는 것이다. 구글은 index에서 어떤 단어 그룹을 찾아봐야 하는지 해석하기 위한 언어 모델을 구축한다. Goole의 Search Quality Evaluator Guidelines를 보면, 동일한 검색어라도 위치에 따라, 시간에 따라, 다를 수 있다는 것을 염두한다.



질의의 의도를 파악하는 것을 중요한 쟁점으로 두고 있는데, 사이사이가 비어있는 러프한 검색어를 보고 의도를 파악해 아주 디테일하게 찾는 작업을 진행한다. 예를 들어, "population or paris"라고 검색했을 때, 해당 결과값은 시간에 따라 바뀔 수 있는 정보다. 구글은 알아서 '현재' 프랑스 파리의 인구를 찾는다.

자연어를 컴퓨터가 이해할 수 있는 명령어로 바꾸는 작업같다. 사용자의 막연한 검색어만으로도 사용자의 의도를 추정하고, 사용자가 원하는 최적의 정보를 제공하기 위해, 사용자의 입장을 분석하고 또 분석하고 있었다. 우리가 구글로부터 검색 결과를 받아보기까지의 과정들 속에 진짜 엄청난 UX가 고려되고 있다는 사실이 어찌나 놀랍던지. 새삼.. 1인자의 자리는 괜히 얻어지는 것이 아니구나 다시금 느꼈다. 래리 페이지는 사용자가 뜻하는 바를 정확하게 이해하고, 사용자가 원하는 것을 제공할 수 있어야 완벽한 검색엔진이라고 했다. Goolge 테스트의 결과에서 일관되게 나타나는 것은 사람들은 검색어에 대한 빠른 결과를 원한다는 점이라고 한다.
다시 돌아가서, 구글이 검색어를 보고 색인에서 어떤 단어 그룹을 찾아봐야 하는지 해석하기 위해 구축한 언어 모델에는 철자 오류 해석과 같은 간단한 단계도 있다.더 나아가 자연어 이해를 위한 최근 연어 결과를 적용해, 사용자가 입력한 검색어의 유형을 인식할 수 있도록 하고 있다. Google의 동의어 시스템을 통해 사용자가 의도하는 단어를 파악한다. 동일하게 '바꾸다'라는 단어로 검색했다 하더라도, 문맥에 적합한 보다 구체적인 단어 '교체하다', '교환하다', '조절하다'라는 단어로 파악하는 것이다. 구글은 모든 언어에 대해 이같은 정교한 과정을 통해 검색 결과를 개선하고 있다.


검색 결과를 구성하는 것
구글은 유용하면서도 공정한 검색결과를 제시한다는 명제를 중요하게 생각하며, 돈 받고 사이트를 index에 추가해주는 일이 없다고 한다. 혹은 업데이트를 더 자주 해주거나, 순위를 높여주는 일도 없다고 한다. (이 대목에서 왜 SEO 최적화라는 키워드가 그렇게 붐이었는지 알 수 있다.)

구글 서치 결과에는 항목별로 제목, URL, 그리고 텍스트의 스니펫(A snippet is a short summary of the content of a website that appears in the Google search results.)이 있어서 개인이 찾던 페이지가 맞는지 쉽게 알 수 있다.
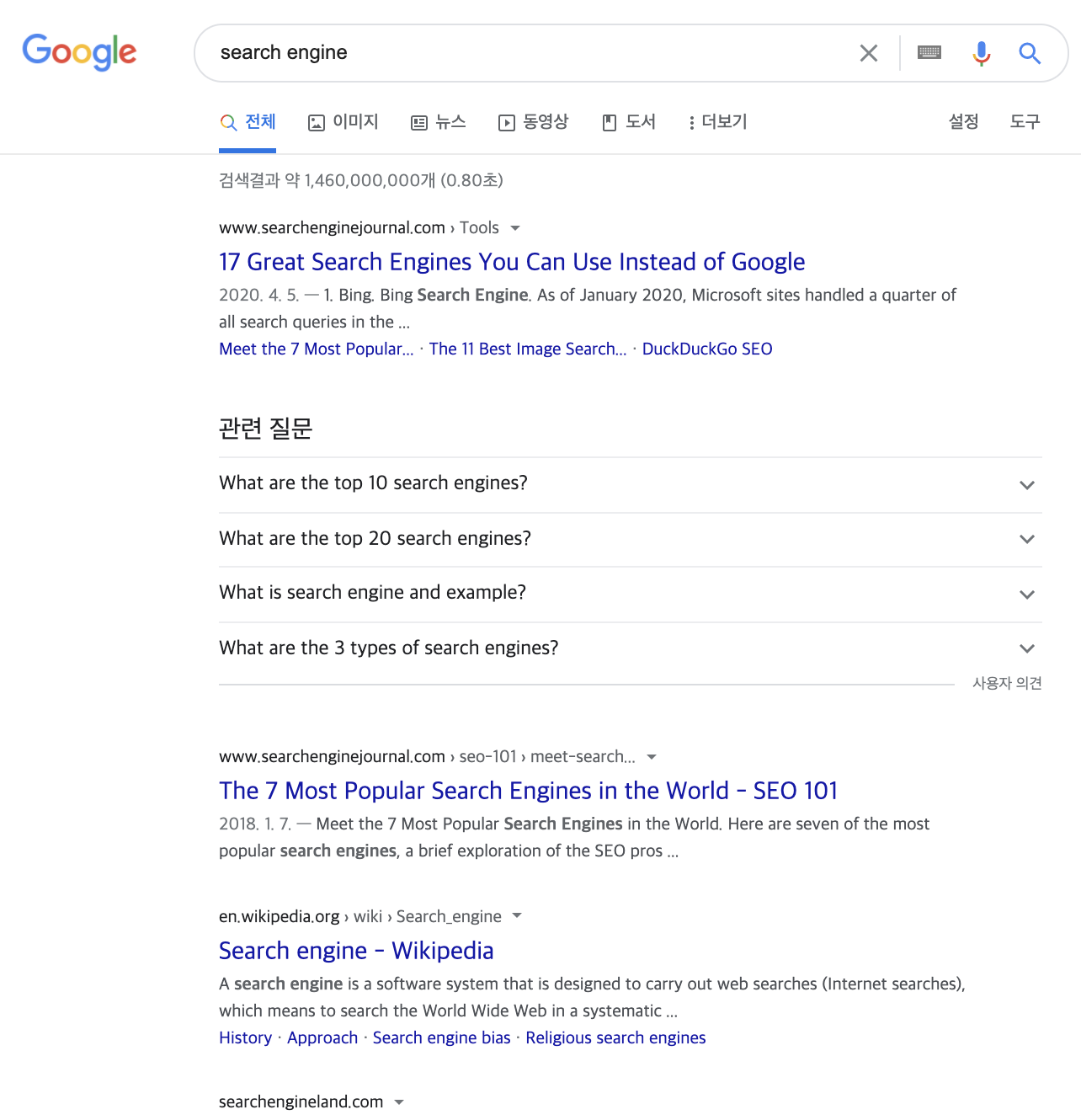

구글에서 'search engine'이라는 검색어를 검색하자, 제목, URL, 텍스트유사 내용의 페이지 링크가 있고, 해당 페이지 내에서 구글이 가장 최근 저장한 페이지도 있다. 하단에는 사용자가 나중에 찾을지 모르는 관련 검색어도 보인다.
또한 오른쪽과 상단에 일반 검색 결과와 차별화된 표시로 광고도 표시된다. 구글은 광고 비즈니스도 아주 중대하게 생각한다. 광고주에게는 가능성 큰 잠재고객을 연결하고, 일반 사용자에게는 원하는 광고만 표시하기 위해 양 방향으로 노력한다.

재미있는 사실은, 사용자가 원하는 정보를 찾지 못하면 아예 광고도 표시하지 않는다고 한다.
크롤링 프로세스
구글의 크롤링 프로세스는, 이전의 크롤링 작업으로 수집한 웹 목록과 웹사이트 소유가자 제공한 * 사이트맵에서 출발한다. 이때 구글은 사이트 소유가자 구글의 크롤링 방법을 세밀하게 설정할 수 있도록 'Search Console'을 제공한다. 웹 사이트 소유는 페이지 크롤링 처리 방식 상세 설정, 재크롤링 요청, 'robots.txt'를 사용해 페이지가 크롤링되지 않도록 설정할 수도 있다.
* 사이트 맵 - 구글이 어떤 URL로 크롤링할지 사이트에 알려주는 신호다. 최근에 생성 또는 수정된 URL 정보를 제공하거나 추가 정보를 제공하는 것이다.
다시 정리해보면,
웹은 계속해서 커지고 있는 정보의 생태계다. 구글은 웹크롤러라는 소프트웨어를 이용해 공개된 웹페이지를 발견하고, 해당 웹페이지에 있는 링크를 따라간다. 크롤러는 여러개의 링크를 넘나들며 웹페이지에 대한 데이터를 구글 서버로 가져온다. 크롤러가 찾아온 이 웹페이지들을 토대로 구글 시스템은 해당 페이지의 콘텐츠를 렌더링한다. 이때 키워드 및 웹사이트 최선 정보에 이르는 주요 신호를 기록하며 검색 index에서 모든 주요 신호를 추적한다. 이를 토대로, 해당 웹페이지에 포함된 모든 단어 하나하나가 구글의 index에 포함된다. 다시 말해, 이미 구글이 보유하고 있는 1억기가 바이트가 넘는 구글의 index 중 웹페이지에 포함된 단어의 index 항목에 웹페이지를 추가하는 것이다.
그리고 사용자가 검색을 하는 순간, 해당 검색어는 구글의 알고리즘을 토대로 의도와 의미가 분석된다. 해당 의도에 최적화된 검색 결과를 찾기 위해, 구글의 복잡한 알고리즘과 질문들은 index에서 정보를 다시 한번 걸러내고 정렬한다. 구글은 단순히 키워드 매칭을 넘어, 사용자가 관심 갖는 인물, 장소, 사물을 더 잘 이해하려고 애쓰며, 웹페이지 정보 외의 다른 유형의 정보도 체계화하고 있다.
여기까지 보고나니, 야후에서 네이버로, 네이버에서 구글로 옮겨간 나의 서치엔진 히스토리를 떠올리며, 서치엔진은 일종의 큐레이션구나 생각했다. 최근 호주에서 가결된 법안, '미디어와 디지털 플랫폼 의무 협상 규정'에 따라, 구글이나 페이스북 같은 거대 디지털 플랫폼이 호주에서 일부 미디어에 한해 뉴스사용료 협상/계약을 맺기 시작했다. 이렇게 이해관계가 대립하는 이유는, 방대한 양의 정보 가운데 양질의 정보를 모으고, 가공하고, 생산하고, 제공하는 일은 언제나 중요했고 앞으로도 중요한 일이기 때문이라 생각된다. 2020년 기준, 구글은 전세계 검색엔진점유율이 92.54%에 달한다고 한다. 2위인 Bing, Yahoo!, Baidu를 합쳐도 5%가 조금 넘는 수치이며, 네이버는 0.07%로 상위10중 가장 낮은 점유율을 차지하고 있다. 나 역시도 구글을 가장 중심적으로 쓰지만, 최근 느끼는 것은 카테고리에 따라 구글이 내게 최적의 정보를 주지는 못한다는 점이었다. 카테고리별로 특화된 서치엔진이 필요한 시점인 것 같다는 생각도 든다.
'💻 Deep Wide Programming > 잡다한 개발 관련 기록' 카테고리의 다른 글
| ELK STACK (0) | 2021.12.17 |
|---|---|
| 중간점검_Reset my Coding Roadmap (1) | 2020.07.28 |
| [생활코딩] UI와 API의 차이 (0) | 2020.07.03 |

